Convolution and ReLU
A convolutional classifier has two parts: a convolutional base and a head of dense layers. We learned that the job of the base is to extract visual features from an image, which the head would then use to classify the image.
We’re going to learn about the two most important types of layers that you’ll usually find in the base of a convolutional image classifier. These are the convolutional layer with ReLU activation, and the maximum pooling layer. Later we’ll learn how to design a convnet by composing these layers into blocks that perform the feature extraction.
Feature Extraction
Before we get into the details of convolution, let’s discuss the purpose of these layers in the network. We’re going to see how these three operations (convolution, ReLU, and maximum pooling) are used to implement the feature extraction process.
The feature extraction performed by the base consists of three basic operations:
- Filter an image for a particular feature (convolution).
- Detect that feature within the filtered image (ReLU).
- Condense the image to enhance the features (maximum pooling). The next figure illustrates this process. You can see how these three operations are able to isolate some particular characteristic of the original image (in this case, horizontal lines).

Typically, the network will perform several extractions in parallel on a single image. In modern convnets, it’s not uncommon for the final layer in the base to be producing over 1000 unique visual features.
Filter with Convolution
A convolutional layer carries out the filtering step. You might define a convolutional layer in a Keras model something like this:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
# More layers follow
])
We can understand these parameters by looking at their relationship to the weights and activations of the layer. Let’s do that now.
Weights
The weights a convnet learns during training are primarily contained in its convolutional layers. These weights we call kernels. We can represent them as small arrays:

A kernel operates by scanning over an image and producing a weighted sum of pixel values. In this way, a kernel will act sort of like a polarized lens, emphasizing or deemphasizing certain patterns of information.

Kernels define how a convolutional layer is connected to the layer that follows. The kernel above will connect each neuron in the output to nine neurons in the input. By setting the dimensions of the kernels with kernel_size, you are telling the convnet how to form these connections. Most often, a kernel will have odd-numbered dimensions – like kernel_size \( =(3, 3) \) or \( (5, 5) \) – so that a single pixel sits at the center, but this is not a requirement.
The kernels in a convolutional layer determine what kinds of features it creates. During training, a convnet tries to learn what features it needs to solve the classification problem. This means finding the best values for its kernels.
Activations
The activations in the network we call feature maps. They are what result when we apply a filter to an image; they contain the visual features the kernel extracts. Here are a few kernels pictured with feature maps they produced.
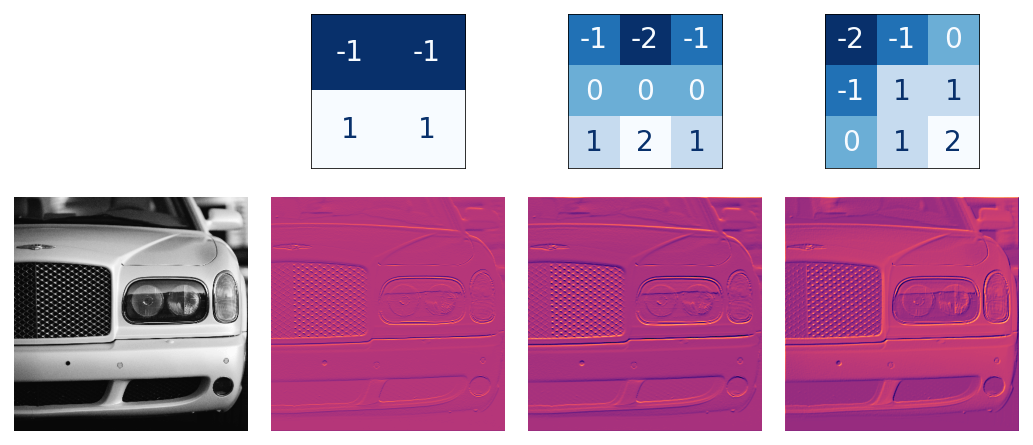
From the pattern of numbers in the kernel, you can tell the kinds of feature maps it creates. Generally, what a convolution accentuates in its inputs will match the shape of the positive numbers in the kernel. The left and middle kernels above will both filter for horizontal shapes.
With the filters parameter, you tell the convolutional layer how many feature maps you want it to create as output.
Detect with ReLU
After filtering, the feature maps pass through the activation function. The rectifier function has a graph like this:
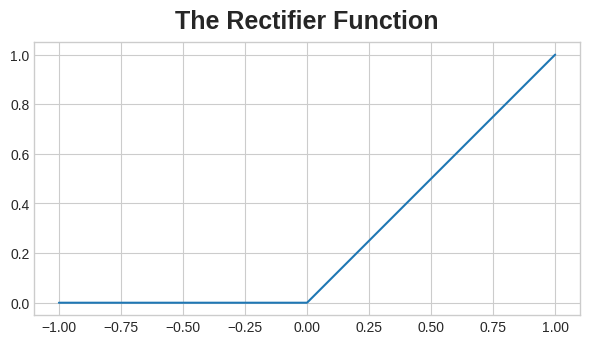
A neuron with a rectifier attached is called a rectified linear unit. For that reason, we might also call the rectifier function the ReLU activation or even the ReLU function.
The ReLU activation can be defined in its own Activation layer, but most often you’ll just include it as the activation function of Conv2D.
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3, activation='relu')
# More layers follow
])
You could think about the activation function as scoring pixel values according to some measure of importance. The ReLU activation says that negative values are not important and so sets them to 0. (“Everything unimportant is equally unimportant.”)
Here is ReLU applied the feature maps above. Notice how it succeeds at isolating the features.

Like other activation functions, the ReLU function is nonlinear. Essentially this means that the total effect of all the layers in the network becomes different than what you would get by just adding the effects together – which would be the same as what you could achieve with only a single layer. The nonlinearity ensures features will combine in interesting ways as they move deeper into the network.
Example - Apply Convolution and ReLU
We’ll do the extraction ourselves in this example to understand better what convolutional networks are doing “behind the scenes”.
Here is the image we’ll use for this example:
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
image_path = '../input/computer-vision-resources/car_feature.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image), cmap='gray')
plt.axis('off')
plt.show();

For the filtering step, we’ll define a kernel and then apply it with the convolution. The kernel in this case is an “edge detection” kernel. You can define it with tf.constant just like you’d define an array in Numpy with np.array. This creates a tensor of the sort TensorFlow uses.
import tensorflow as tf
kernel = tf.constant([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
])
plt.figure(figsize=(3, 3))
show_kernel(kernel)

TensorFlow includes many common operations performed by neural networks in its tf.nn module. The two that we’ll use are conv2d and relu. These are simply function versions of Keras layers.
This next cell does some reformatting to make things compatible with TensorFlow. The details aren’t important for this example
# Reformat for batch compatibility.
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.expand_dims(image, axis=0)
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
kernel = tf.cast(kernel, dtype=tf.float32)
Now let’s apply our kernel and see what happens.
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
# we'll talk about these two in lesson 4!
strides=1,
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_filter))
plt.axis('off')
plt.show();

Next is the detection step with the ReLU function. This function is much simpler than the convolution, as it doesn’t have any parameters to set.
image_detect = tf.nn.relu(image_filter)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.show();

And now we’ve created a feature map! Images like these are what the head uses to solve its classification problem. We can imagine that certain features might be more characteristic of Cars and others more characteristic of Trucks. The task of a convnet during training is to create kernels that can find those features.
We’ve now seen the first two steps a convnet uses to perform feature extraction: filter with Conv2D layers and detect with relu activation.
Example
We’ll work on building some intuition around feature extraction. First, we’ll walk through the example we did in the previous example again, but this time, with a kernel you choose yourself. We’ve mostly been working with images in this course, but what’s behind all of the operations we’re learning about is mathematics. So, we’ll also take a look at how these feature maps can be represented instead as arrays of numbers and what effect convolution with a kernel will have on them.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
tf.config.run_functions_eagerly(True)
Apply Transformations
image_path = '../input/computer-vision-resources/car_illus.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image, channels=1)
image = tf.image.resize(image, size=[400, 400])
img = tf.squeeze(image).numpy()
plt.figure(figsize=(6, 6))
plt.imshow(img, cmap='gray')
plt.axis('off')
plt.show();
import learntools.computer_vision.visiontools as visiontools
from learntools.computer_vision.visiontools import edge, bottom_sobel, emboss, sharpen
kernels = [edge, bottom_sobel, emboss, sharpen]
names = ["Edge Detect", "Bottom Sobel", "Emboss", "Sharpen"]
plt.figure(figsize=(12, 12))
for i, (kernel, name) in enumerate(zip(kernels, names)):
plt.subplot(1, 4, i+1)
visiontools.show_kernel(kernel)
plt.title(name)
plt.tight_layout()
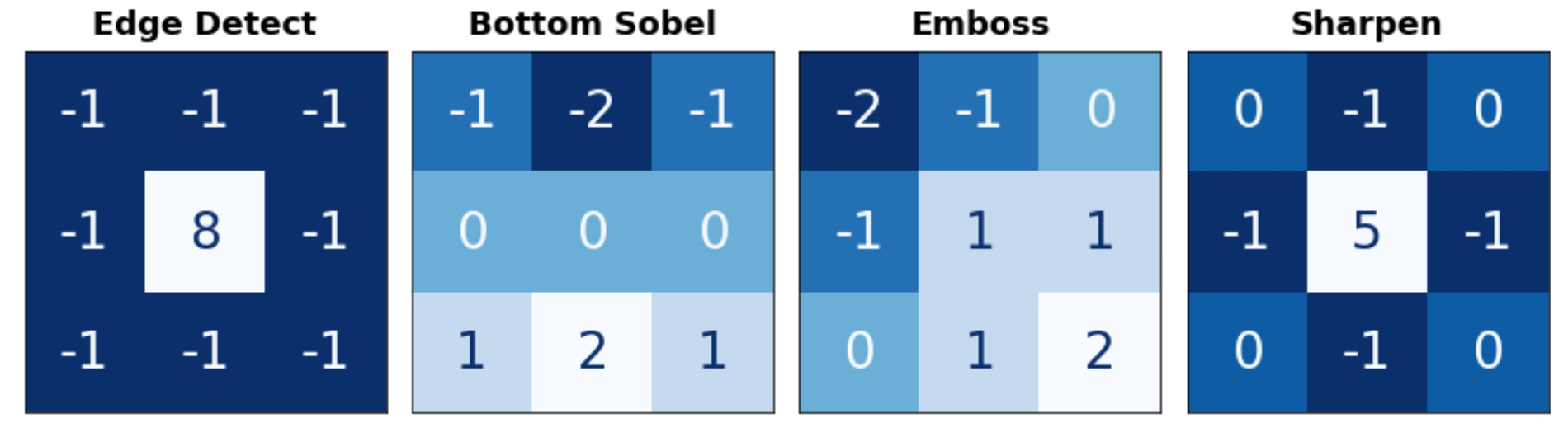
Define Kernel
Use the next code cell to define a kernel. You have your choice of what kind of kernel to apply. One thing to keep in mind is that the sum of the numbers in the kernel determines how bright the final image is. Generally, you should try to keep the sum of the numbers between 0 and 1 (though that’s not required for a correct answer).
In general, a kernel can have any number of rows and columns. For this exercise, let’s use a 3×3 kernel, which often gives the best results. Define a kernel with tf.constant.
# This is just one possibility.
kernel = tf.constant([
[-2, -1, 0],
[-1, 1, 1],
[0, 1, 2],
])
Now we’ll do the first step of feature extraction, the filtering step. First run this cell to do some reformatting for TensorFlow.
# Reformat for batch compatibility.
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.expand_dims(image, axis=0)
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
kernel = tf.cast(kernel, dtype=tf.float32)
Apply Convolution
Now we’ll apply the kernel to the image by a convolution. The layer in Keras that does this is layers.Conv2D. What is the backend function in TensorFlow that performs the same operation?
conv_fn = tf.nn.conv2d
Once you’ve got the correct answer, run this next cell to execute the convolution and see the result!
image_filter = conv_fn(
input=image,
filters=kernel,
strides=1, # or (1, 1)
padding='SAME',
)
plt.imshow(
# Reformat for plotting
tf.squeeze(image_filter)
)
plt.axis('off')
plt.show();
Apply ReLU
Now detect the feature with the ReLU function. In Keras, you’ll usually use this as the activation function in a Conv2D layer. What is the backend function in TensorFlow that does the same thing?
relu_fn = tf.nn.relu
The image you see below is the feature map produced by the kernel you chose. If you like, experiment with some of the other suggested kernels above, or, try to invent one that will extract a certain kind of feature.

In the tutorial, our discussion of kernels and feature maps was mainly visual. We saw the effect of Conv2D and ReLU by observing how they transformed some example images.
But the operations in a convolutional network (like in all neural networks) are usually defined through mathematical functions, through a computation on numbers. In the next exercise, we’ll take a moment to explore this point of view.
Let’s start by defining a simple array to act as an image, and another array to act as the kernel. Run the following cell to see these arrays.
# Sympy is a python library for symbolic mathematics. It has a nice
# pretty printer for matrices, which is all we'll use it for.
import sympy
sympy.init_printing()
from IPython.display import display
image = np.array([
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 0, 1, 1, 1],
[0, 1, 0, 0, 0, 0],
])
kernel = np.array([
[1, -1],
[1, -1],
])
display(sympy.Matrix(image))
display(sympy.Matrix(kernel))
# Reformat for Tensorflow
image = tf.cast(image, dtype=tf.float32)
image = tf.reshape(image, [1, *image.shape, 1])
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
kernel = tf.cast(kernel, dtype=tf.float32)
Observe Convolution on a Numerical Matrix
What do you see? The image is simply a long vertical line on the left and a short horizontal line on the lower right. What about the kernel? What effect do you think it will have on this image? After you’ve thought about it, run the next cell for the answer.
In the tutorial, we talked about how the pattern of positive numbers will tell you the kind of features the kernel will extract. This kernel has a vertical column of 1’s, and so we would expect it to return features of vertical lines.
Now let’s try it out. Run the next cell to apply convolution and ReLU to the image and display the result.
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
strides=1,
padding='VALID',
)
image_detect = tf.nn.relu(image_filter)
# The first matrix is the image after convolution, and the second is
# the image after ReLU.
display(sympy.Matrix(tf.squeeze(image_filter).numpy()))
display(sympy.Matrix(tf.squeeze(image_detect).numpy()))
In this lesson, we learned about the first two operations a convolutional classifier uses for feature extraction: filtering an image with a convolution and detecting the feature with the rectified linear unit.