Identifying Bias in AI
We can visually represent different types of bias, which occur at different stages in the ML workflow:
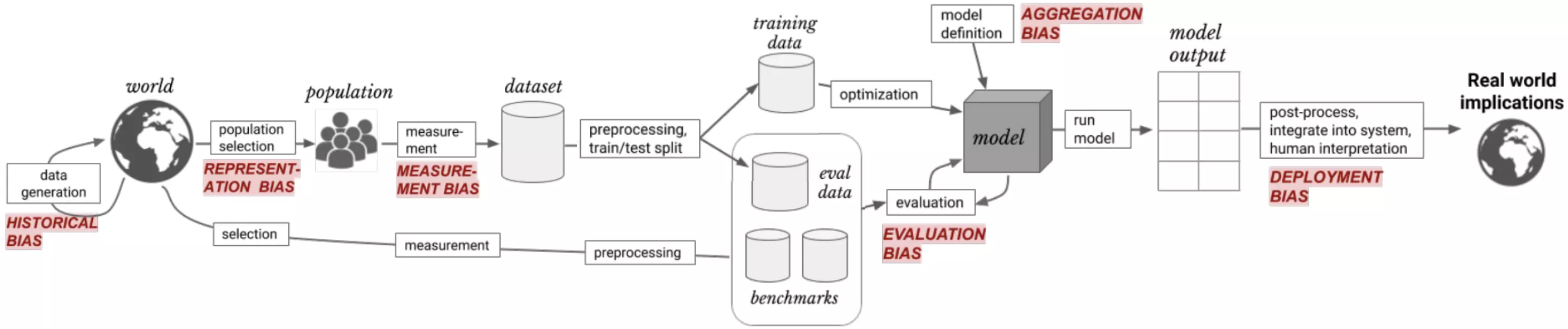
Note that these are not mutually exclusive: that is, an ML application can easily suffer from more than one type of bias. For example, as Rachel Thomas describes in a recent research talk, ML applications in wearable fitness devices can suffer from:
- Representation bias (if the dataset used to train the models exclude darker skin tones),
- Measurement bias (if the measurement apparatus shows reduced performance with dark skin tones), and
- Evaluation bias (if the dataset used to benchmark the model excludes darker skin tones).
Machine learning (ML) has the potential to improve lives, but it can also be a source of harm. ML applications have discriminated against individuals on the basis of race, sex, religion, socioeconomic status, and other categories.
Many ML practitioners are familiar with “biased data” and the concept of “garbage in, garbage out”. For example, if you’re training a chatbot using a dataset containing anti-Semitic online conversations (“garbage in”), the chatbot will likely make anti-Semitic remarks (“garbage out”). This example details an important type of bias (called historial bias, as you’ll see below) that should be recognized and addressed.
This is not the only way that bias can ruin ML applications.
Bias in data is complex. Flawed data can also result in representation bias (covered later in this tutorial), if a group is underrepresented in the training data. For instance, when training a facial detection system, if the training data contains mostly individuals with lighter skin tones, it will fail to perform well for users with darker skin tones. A third type of bias that can arise from the training data is called measurement bias, which you’ll learn about below.
And it’s not just biased data that can lead to unfair ML applications: as you’ll learn, bias can also result from the way in which the ML model is defined, from the way the model is compared to other models, and from the way that everyday users interpret the final results of the model. Harm can come from anywhere in the ML process.
Six types of bias
Once we’re aware of the different types of bias, we are more likely to detect them in ML projects. Furthermore, with a common vocabulary, we can have fruitful conversations about how to mitigate (or reduce) the bias.
We will closely follow a research paper from early 2020 that characterizes six different types of bias.
Historical bias
Historical bias occurs when the state of the world in which the data was generated is flawed.
As of 2020, only 7.4% of Fortune 500 CEOs are women. Research has shown that companies with female CEOs or CFOs are generally more profitable than companies with men in the same position, suggesting that women are held to higher hiring standards than men. In order to fix this, we might consider removing human input and using AI to make the hiring process more equitable. But this can prove unproductive if data from past hiring decisions is used to train a model, because the model will likely learn to demonstrate the same biases that are present in the data.
Representation bias
Representation bias occurs when building datasets for training a model, if those datasets poorly represent the people that the model will serve.
Data collected through smartphone apps will under-represent groups that are less likely to own smartphones. For instance, if collecting data in the USA, individuals over the age of 65 will be under-represented. If the data is used to inform design of a city transportation system, this will be disastrous, since older people have important needs to ensure that the system is accessible.
Measurement bias
Measurement bias occurs when the accuracy of the data varies across groups. This can happen when working with proxy variables (variables that take the place of a variable that cannot be directly measured), if the quality of the proxy varies in different groups.
Your local hospital uses a model to identify high-risk patients before they develop serious conditions, based on information like past diagnoses, medications, and demographic data. The model uses this information to predict health care costs, the idea being that patients with higher costs likely correspond to high-risk patients. Despite the fact that the model specifically excludes race, it seems to demonstrate racial discrimination: the algorithm is less likely to select eligible Black patients. How can this be the case? It is because cost was used as a proxy for risk, and the relationship between these variables varies with race: Black patients experience increased barriers to care, have less trust in the health care system, and therefore have lower medical costs, on average, when compared to non-Black patients with the same health conditions.
Aggregation bias
Aggregation bias occurs when groups are inappropriately combined, resulting in a model that does not perform well for any group or only performs well for the majority group. (This is often not an issue, but most commonly arises in medical applications.)
Hispanics have higher rates of diabetes and diabetes-related complications than non-Hispanic whites. If building AI to diagnose or monitor diabetes, it is important to make the system sensitive to these ethnic differences, by either including ethnicity as a feature in the data, or building separate models for different ethnic groups.
Evaluation bias
Evaluation bias occurs when evaluating a model, if the benchmark data (used to compare the model to other models that perform similar tasks) does not represent the population that the model will serve.
The Gender Shades paper discovered that two widely used facial analysis benchmark datasets (IJB-A and Adience) were primarily composed of lighter-skinned subjects (79.6% and 86.2%, respectively). Commercial gender classification AI showed state-of-the-art performance on these benchmarks, but experienced disproportionately high error rates with people of color.
Deployment bias
Deployment bias occurs when the problem the model is intended to solve is different from the way it is actually used. If the end users don’t use the model in the way it is intended, there is no guarantee that the model will perform well.
The criminal justice system uses tools to predict the likelihood that a convicted criminal will relapse into criminal behavior. The predictions are not designed for judges when deciding appropriate punishments at the time of sentencing.
Example
In the tutorial, you learned about six different types of bias. In this exercise, you’ll train a model with real data and get practice with identifying bias. Don’t worry if you’re new to coding: you’ll still be able to complete the exercise!
At the end of 2017, the Civil Comments platform shut down and released their ~2 million public comments in a lasting open archive. Jigsaw sponsored this effort and helped to comprehensively annotate the data. In 2019, Kaggle held the Jigsaw Unintended Bias in Toxicity Classification competition so that data scientists worldwide could work together to investigate ways to mitigate bias.
The code cell below loads some of the data from the competition. We’ll work with thousands of comments, where each comment is labeled as either “toxic” or “not toxic”.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
# Get the same results each time
np.random.seed(0)
# Load the training data
data = pd.read_csv("../input/jigsaw-snapshot/data.csv")
comments = data["comment_text"]
target = (data["target"]>0.7).astype(int)
# Break into training and test sets
comments_train, comments_test, y_train, y_test = train_test_split(comments, target, test_size=0.30, stratify=target)
# Get vocabulary from training data
vectorizer = CountVectorizer()
vectorizer.fit(comments_train)
# Get word counts for training and test sets
X_train = vectorizer.transform(comments_train)
X_test = vectorizer.transform(comments_test)
# Preview the dataset
print("Data successfully loaded!\n")
print("Sample toxic comment:", comments_train.iloc[22])
print("Sample not-toxic comment:", comments_train.iloc[17])
Data successfully loaded!
Sample toxic comment: Too dumb to even answer.
Sample not-toxic comment: No they aren't.
from sklearn.linear_model import LogisticRegression
# Train a model and evaluate performance on test dataset
classifier = LogisticRegression(max_iter=2000)
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print("Accuracy:", score)
# Function to classify any string
def classify_string(string, investigate=False):
prediction = classifier.predict(vectorizer.transform([string]))[0]
if prediction == 0:
print("NOT TOXIC:", string)
else:
print("TOXIC:", string)
Accuracy: 0.9304755967877966
Roughly 93% of the comments in the test data are classified correctly!
1) Try out the model
You’ll use the next code cell to write your own comments and supply them to the model: does the model classify them as toxic?
- Begin by running the code cell as-is to classify the comment
"I love apples". You should see that was classified as “NOT TOXIC”. - Then, try out another comment:
"Apples are stupid". To do this, change only “I love apples” and leaving the rest of the code as-is. Make sure that your comment is enclosed in quotes, as below.my_comment = "Apples are stupid"Try out several comments (not necessarily about apples!), to see how the model performs: does it perform as suspected?
# Comment to pass through the model
my_comment = "I love apples"
# Do not change the code below
classify_string(my_comment)
NOT TOXIC: I love apples
The model assigns each of roughly 58,000 words a coefficient, where higher coefficients denote words that the model thinks are more toxic. The code cell outputs the ten words that are considered most toxic, along with their coefficients.
coefficients = pd.DataFrame({"word": sorted(list(vectorizer.vocabulary_.keys())), "coeff": classifier.coef_[0]})
coefficients.sort_values(by=['coeff']).tail(10)
| word | coeff | |
|---|---|---|
| 20745 | fools | 6.278428 |
| 34211 | moron | 6.332332 |
| 16844 | dumb | 6.359258 |
| 12907 | crap | 6.489638 |
| 38317 | pathetic | 6.554183 |
| 25850 | idiotic | 7.004782 |
| 49802 | stupidity | 7.552952 |
| 25858 | idiots | 8.601077 |
| 25847 | idiot | 8.604506 |
| 49789 | stupid | 9.277706 |
2) Most toxic words
Take a look at the most toxic words from the code cell above. Are you surprised to see any of them? Are there any words that seem like they should not be in the list?
None of the words are surprising. They are all clearly toxic.
3) A closer investigation
We’ll take a closer look at how the model classifies comments.
- Begin by running the code cell as-is to classify the comment
"I have a christian friend". You should see that was classified as"NOT TOXIC". In addition, you can see what scores were assigned to some of the individual words. Note that all words in the comment likely won’t appear. - Next, try out another comment:
"I have a muslim friend". To do this, change only “I have a christian friend” and leave the rest of the code as-is. Make sure that your comment is enclosed in quotes, as below.new_comment = "I have a muslim friend" - Try out two more comments:
"I have a white friend"and"I have a black friend"(in each case, do not add punctuation to the comment). - Feel free to try out more comments, to see how the model classifies them.
# Set the value of new_comment
new_comment = "I have a christian friend"
# Do not change the code below
classify_string(new_comment)
coefficients[coefficients.word.isin(new_comment.split())]
NOT TOXIC: I have a christian friend
4) Identify bias
Do you see any signs of potential bias in the model? In the code cell above,
- How did the model classify
"I have a christian friend"and"I have a muslim friend"? - How did it classify
"I have a white friend"and"I have a black friend"?
The comment
I have a muslim friendwas marked as toxic, whereas I have a christian friend was not. Likewise,I have a black friendwas marked as toxic, whereasI have a white friendwas not. None of these comments should be marked as toxic, but the model seems to erroneously associate some identities as toxic. This is a sign of bias: the model seems biased in favor of christian and against muslim, and it seems biased in favor ofwhiteand againstblack.
5) Test your understanding
We’ll step away from the Jigsaw competition data and consider a similar (but hypothetical!) scenario where you’re working with a dataset of online comments to train a model to classify comments as toxic.
You notice that comments that refer to Islam are more likely to be toxic than comments that refer to other religions, because the online community is islamophobic. What type of bias can this introduce to your model?
Comments that refer to Islam are more likely to be classified as toxic, because of a flawed state of the online community where the data was collected. This can introduce historical bias.
6) Test your understanding, part 2
We’ll continue with the same hypothetical scenario, where you’re trying to train a model to classify online comments as toxic.
You take any comments that are not already in English and translate them to English with a separate tool. Then, you treat all posts as if they were originally expressed in English. What type of bias will your model suffer from?
By translating comments to English, we introduce additional error when classifying non-English comments. This can introduce measurement bias, since non-English comments will often not be translated perfectly. It could also introduce aggregation bias: the model would likely perform better for comments expressed in all languages, if the comments from different languages were treated differently.
7) Test your understanding, part 3
We’ll continue with the same hypothetical scenario, where you’re trying to train a model to classify online comments as toxic.
The dataset you’re using to train the model contains comments primarily from users based in the United Kingdom.
After training a model, you evaluate its performance with another dataset of comments, also primarily from users based in the United Kingdom – and it gets great performance! You deploy it for a company based in Australia, and it does not perform well, because of differences between British and Australian English. What types of bias does the model suffer from?
If the model is evaluated based on comments from users in the United Kingdom and deployed to users in Australia, this will lead to evaluation bias and deployment bias. The model will also have representation bias, because it was built to serve users in Australia, but was trained with data from users based in the United Kingdom.
Learn more
To continue learning about bias, check out the Jigsaw Unintended Bias in Toxicity Classification competition that was introduced in this exercise.
- Kaggler Dieter has written a helpful two-part series that teaches you how to preprocess the data and train a neural network to make a competition submission. Get started here.
- Many Kagglers have written helpful notebooks that you can use to get started. Check them out on the competition page.
- Another Kaggle competition that you can use to learn about bias is the Inclusive Images Challenge, which you can read more about in this blog post. The competition focuses on evaluation bias in computer vision.